เมื่อข้อมูลวิจัยและทุนถูกจัดโครงก่อนส่งให้ AI การวิเคราะห์ก็มีคุณภาพขึ้น
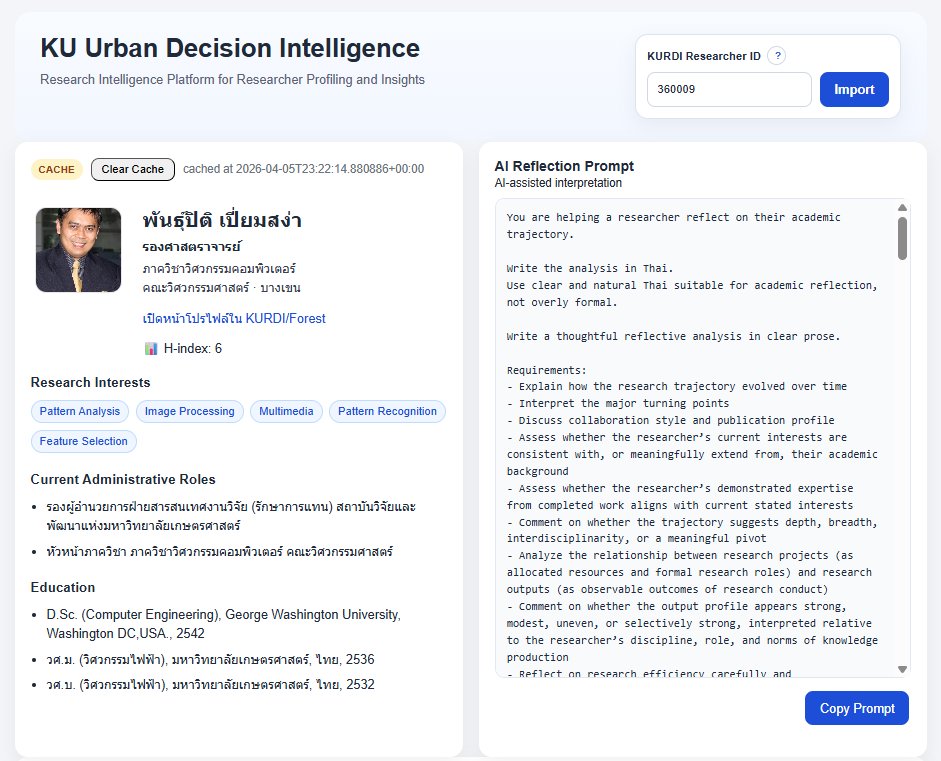
บทความนี้เริ่มจากการทดลองเล่นกับข้อมูลจาก KURDI API แต่กลายเป็นกรณีศึกษาจริงของการใช้ AI กับข้อมูลวิจัย โดยโฟกัสที่ข้อมูลทุนวิจัยและผลงานซึ่งมีตัวแปรจำนวนมากและเงื่อนไขซับซ้อนเกินกว่าจะโยนเข้าโมเดลแบบตรง ๆ แล้วหวังผลวิเคราะห์ที่ดีได้
ข้อค้นพบสำคัญคือ ถ้าต้องการให้ AI วิเคราะห์ดีพอ เราต้องป้อนบริบทให้ครบ จึงเกิดแนวทางที่เปลี่ยนจากการยิง AI ตรง ๆ ไปเป็นการสร้างprompt ขนาดใหญ่จากข้อมูลที่ถูกจัดโครงเรียบร้อยแล้ว แล้วค่อยส่งต่อให้โมเดลวิเคราะห์อีกที
วิธีคิดนี้ชี้ว่าคุณค่าของ AI ไม่ได้อยู่ที่การปล่อยให้โมเดลเดาเองจากข้อมูลดิบ แต่ขึ้นกับการออกแบบdata pipelineและcontext ที่เหมาะสมเสียก่อน เมื่อข้อมูลถูกเรียบเรียงในรูปที่ช่วยให้โมเดลเข้าใจความสัมพันธ์ระหว่างตัวแปรได้ดีขึ้น ผลลัพธ์เชิงวิเคราะห์ก็มีแนวโน้มจะลึกและใช้งานได้จริงมากกว่า
Large prompt อาจบ้าน ๆ แต่ตอบโจทย์การวิเคราะห์ที่มีบริบท
แม้ทางเทคนิคจะสามารถต่อระบบให้ AI ตอบกลับในเว็บได้โดยตรง แต่โพสต์นี้ชี้ให้เห็นทางเลือกที่pragmaticกว่า คือใช้วิธีแบบบ้าน ๆ ก่อน ด้วยการให้ผู้ใช้copy promptไปวางใน ChatGPT หรือ Gemini เอง วิธีนี้อาจไม่หรู แต่ช่วยทดสอบแนวคิดได้เร็วและไม่เพิ่มต้นทุนโดยไม่จำเป็น
ในแง่นี้ งานชิ้นนี้จึงไม่ใช่แค่เดโมสนุก ๆ แต่เป็นตัวอย่างของการค่อย ๆ สร้างAI-enabled workflow ที่เริ่มจากของง่าย ใช้ได้จริง และเปิดให้ผู้ใช้ช่วยสะท้อนว่า insight ที่ได้มีคุณค่ามากพอจะต่อยอดเป็นระบบเต็มรูปแบบหรือไม่
หัวใจไม่ใช่แค่ AI เก่ง แต่คือการทำให้ AI เห็นข้อมูลในโครงที่ถูกต้อง
สารสำคัญของบทความนี้จึงอยู่ที่การเตือนว่า ถ้าจะใช้ AI กับงานวิเคราะห์ข้อมูลวิจัยอย่างจริงจัง เราไม่ควรถามแค่ว่าโมเดลตอบอะไรได้ แต่ต้องถามก่อนว่าเราออกแบบบริบทให้มันมองเห็นข้อมูลอย่างถูกต้องแล้วหรือยัง
เมื่อมองเช่นนี้ ความก้าวหน้าของระบบวิเคราะห์ไม่ได้อยู่ที่ตัว AI เพียงอย่างเดียว แต่อยู่ที่ความสามารถในการจัดโครงข้อมูล สร้าง prompt ที่ดี และออกแบบระบบให้คนสามารถใช้ AI เพื่อค้นหาinsight ที่มีความหมายกับงานของตัวเองได้จริง